Data Factory Pipeline
- 19 Nov 2024
- 4 Minutes to read
- Print
- DarkLight
- Download PDF
Data Factory Pipeline
- Updated on 19 Nov 2024
- 4 Minutes to read
- Print
- DarkLight
- Download PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Introduction
A pipeline is a logical collection of activities that work together to complete a task. A pipeline, for example, could include a set of activities that ingest and clean log data before launching a mapping data flow to analyze the log data.
The pipeline enables users to manage the activities as a group rather than being individual.
Run Pipeline
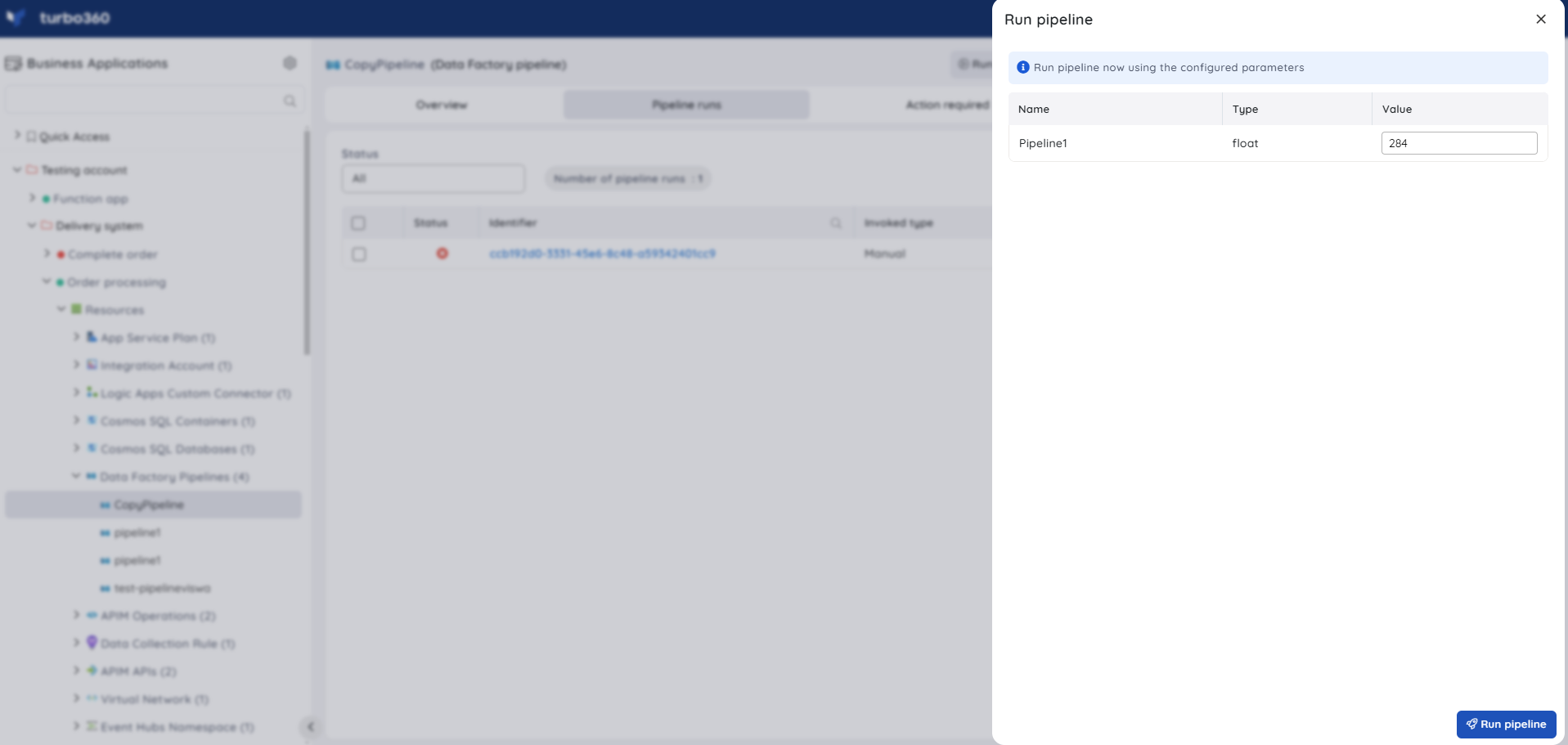
The Run pipeline option available at the top of the section allows users to trigger a Data Factory Pipeline by providing values to the parameters configured using the Azure portal.
Pipeline Runs
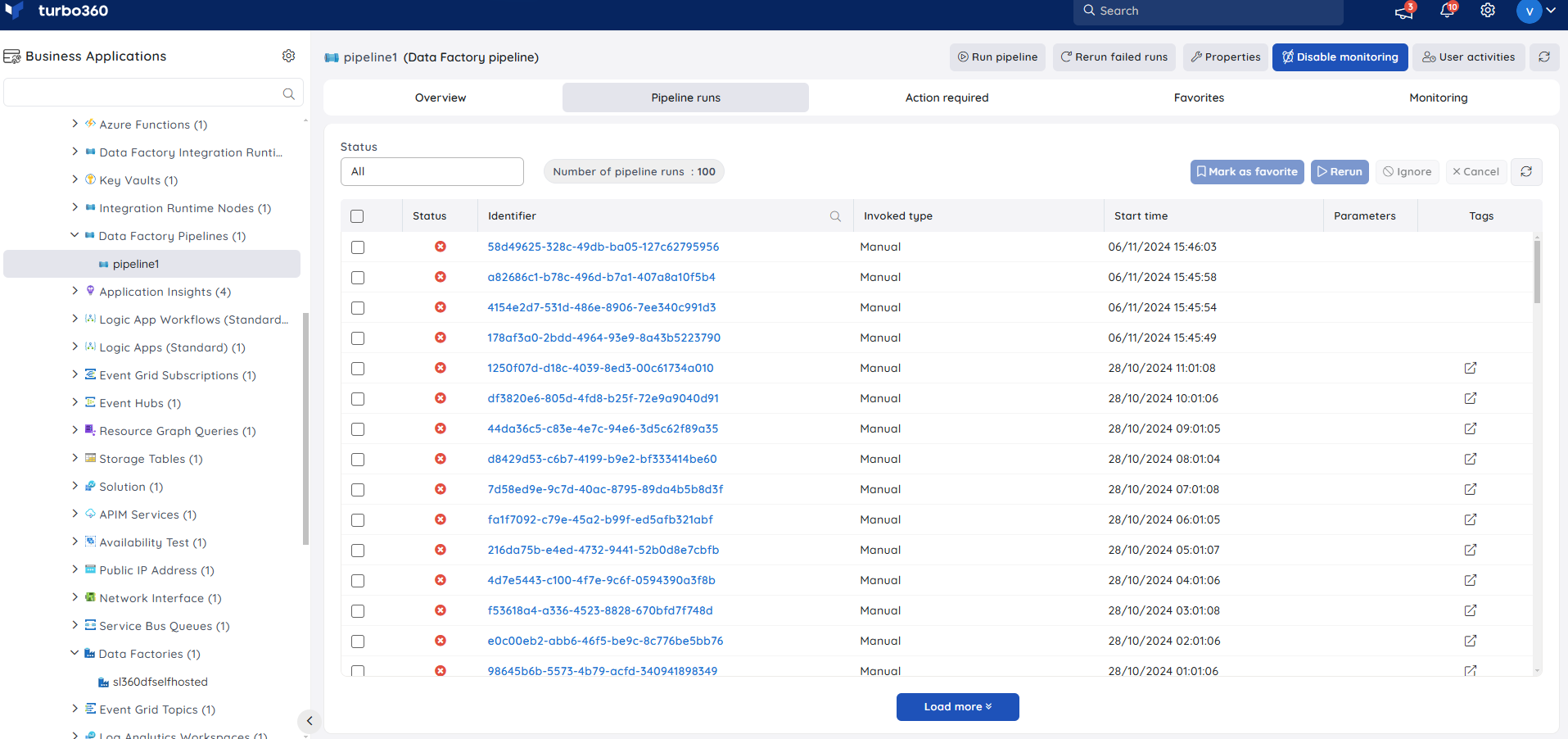
Switch to the Pipeline runs tab to have detailed insights on the status of all the pipeline runs triggered.
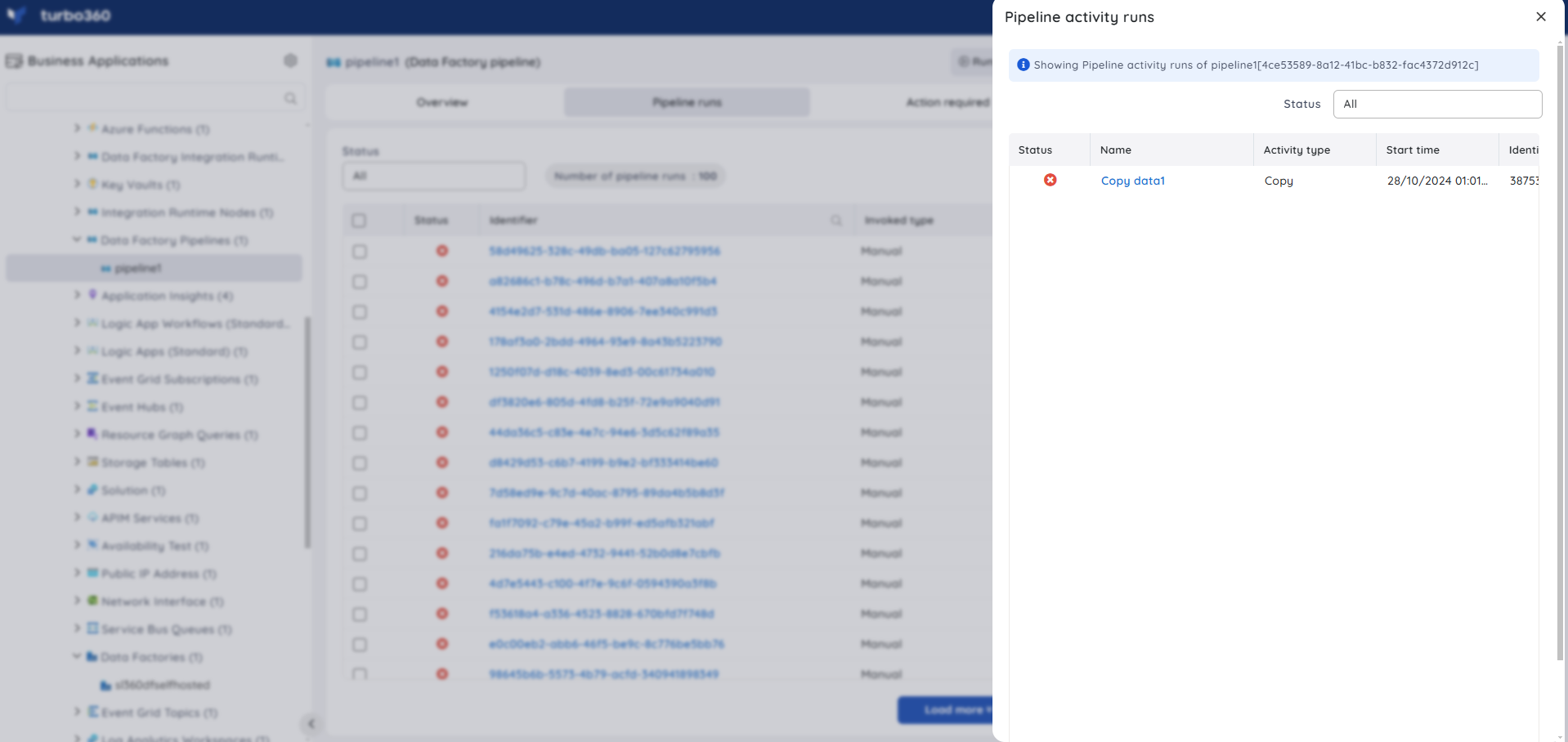
Clicking on a pipeline run will reveal the status of each activity within the pipeline.
Parameters
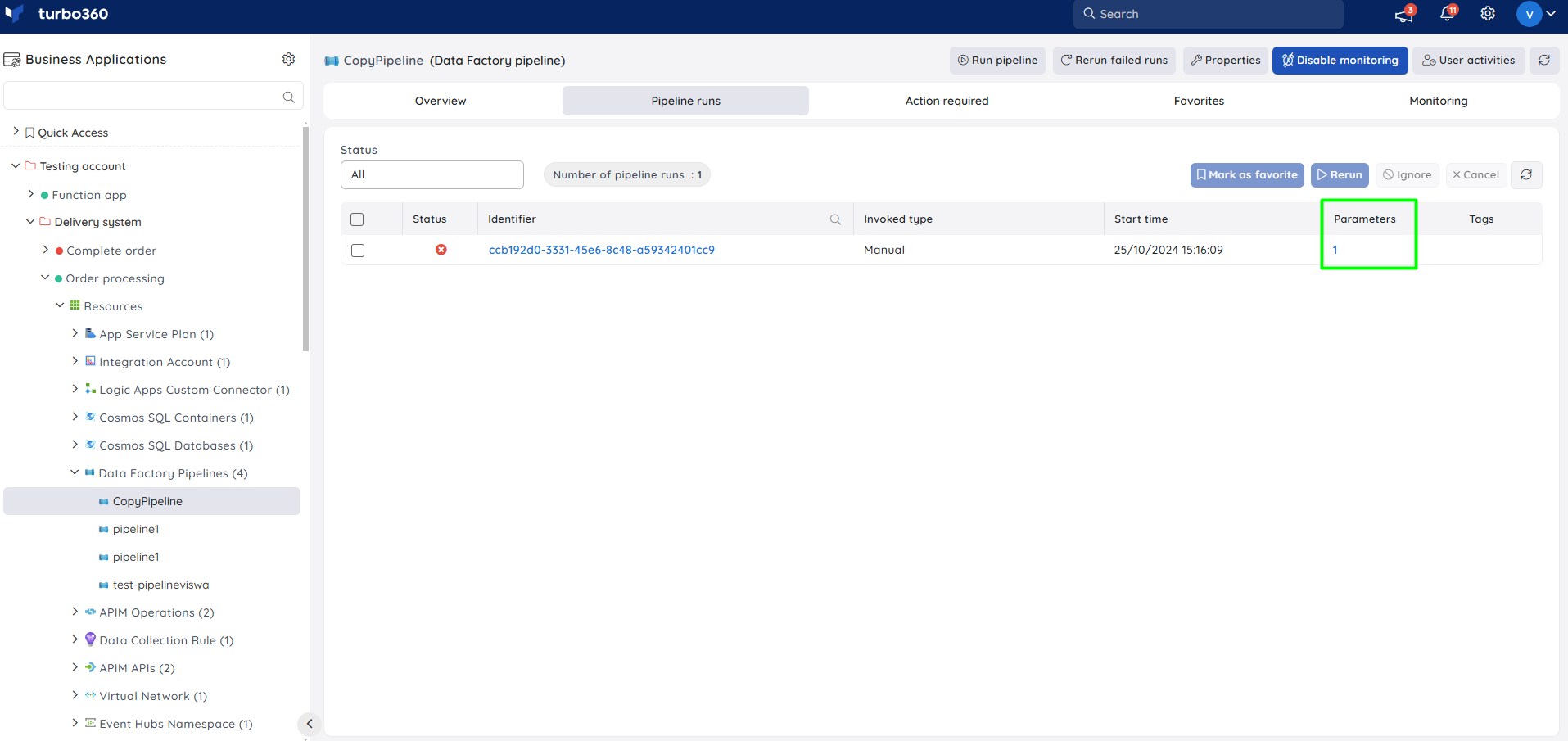
The parameters set when triggering a pipeline will appear in the Parameters column for that pipeline run.
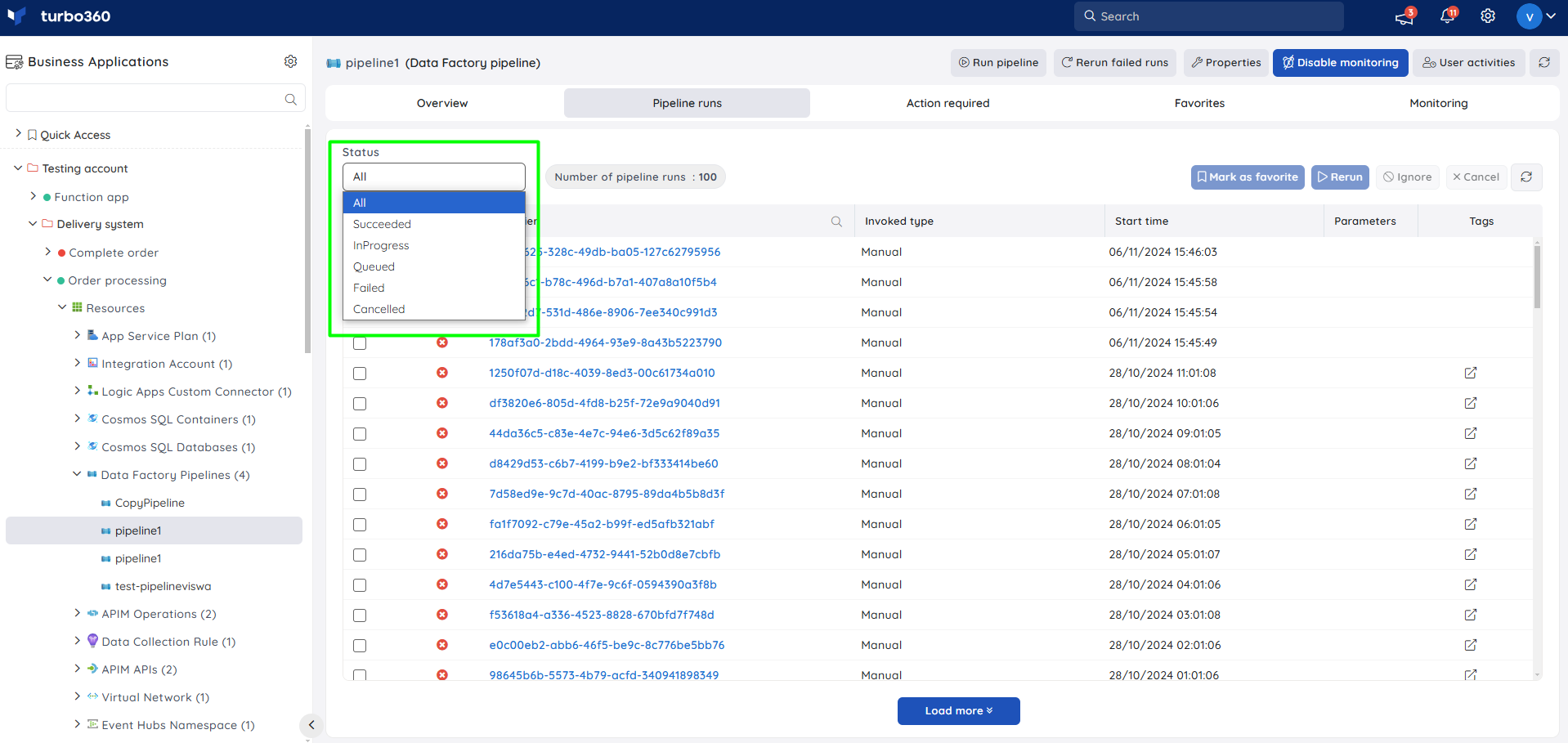
Filtering
The pipeline runs can be filtered based any one of the following statuses:
- Succeeded
- In Progress
- Queued
- Failed
- Cancelled
Rerun failed pipeline runs
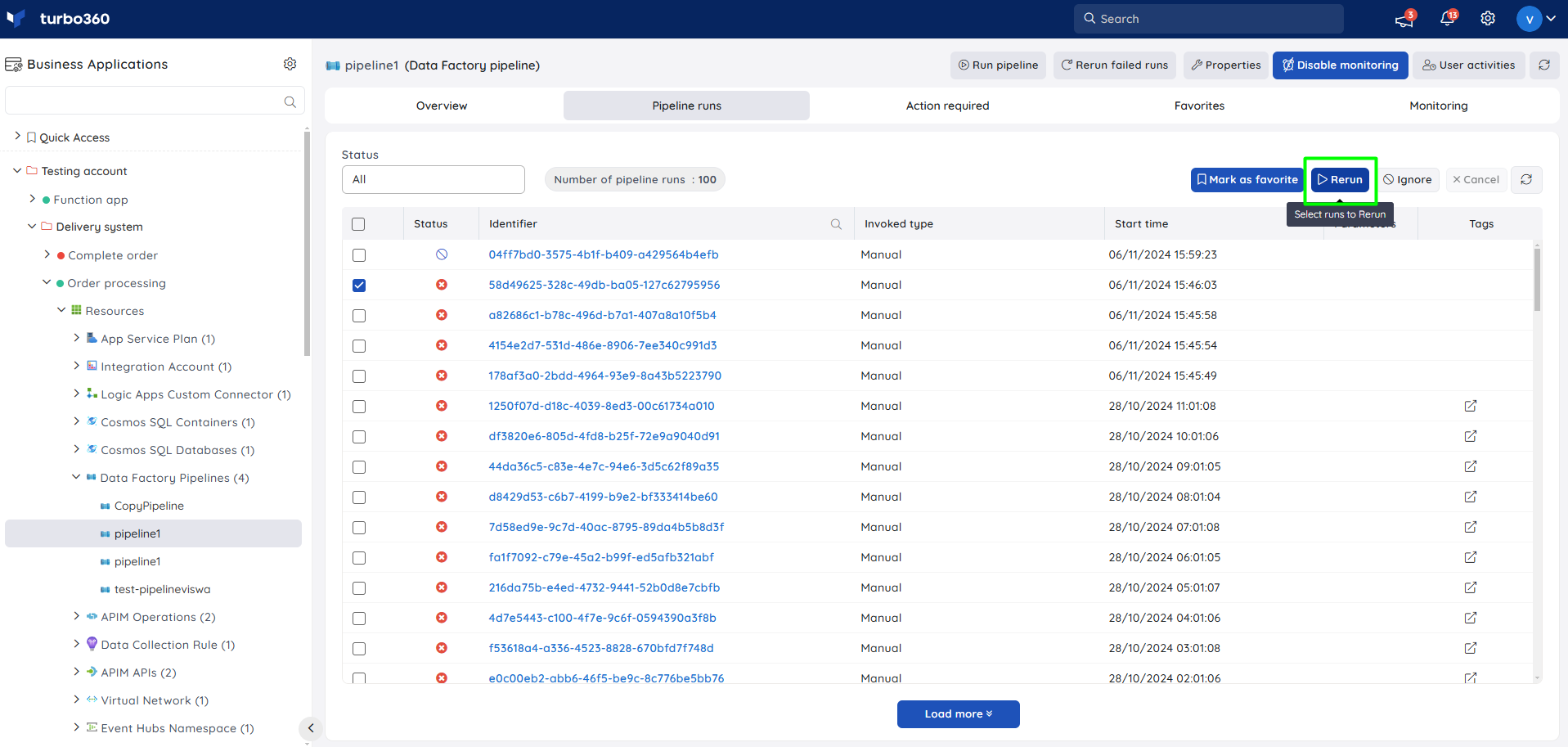
Pipelines can be re-run by using the configured parameters for the respective runs.
A Data Factory Pipeline run might fail due to failure in any of its activities and it occurs quite often in a business orchestration. Turbo360 already facilitates viewing the run history and accessing the details of the failed activity runs. There may be a need to rerun failed activity runs, and Turbo360 allows users to run single or multiple pipeline runs.
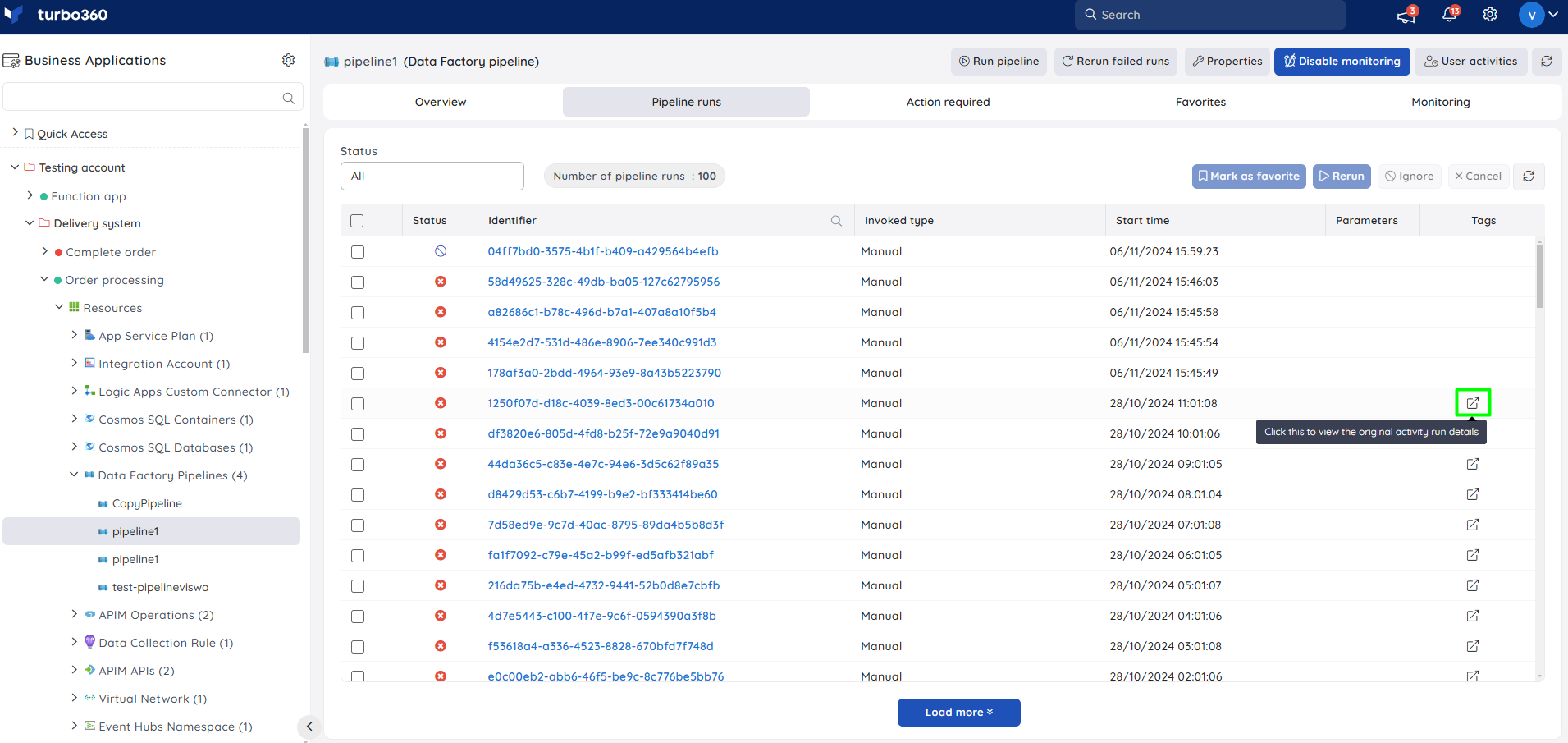
Once the re-run operation is complete, a tag that allows users to retrieve the details of the original activity run is added to the child run. The parent pipeline run contains a tag that allows users to view the run history of all its child runs.
Regardless of how many child runs are re-run, only one pipeline run acts as the original activity run for the child runs.
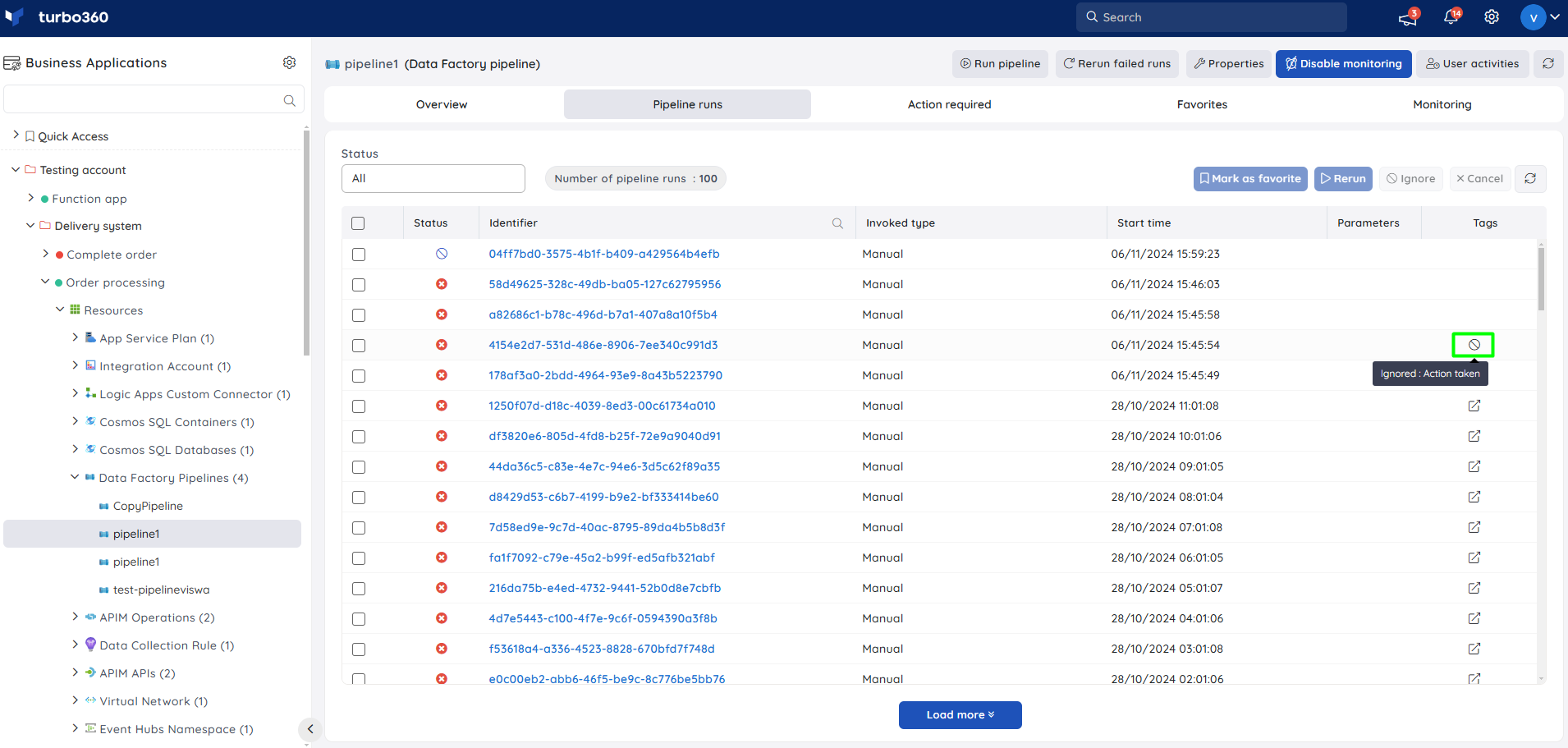
Ignore pipeline run
Pipeline runs can also be ignored in Turbo360. Once ignored, an ignored tag gets associated with the particular run along with the provided description.
Ignore tag is visible only in Turbo360 and will not have any impact on the actual runs.
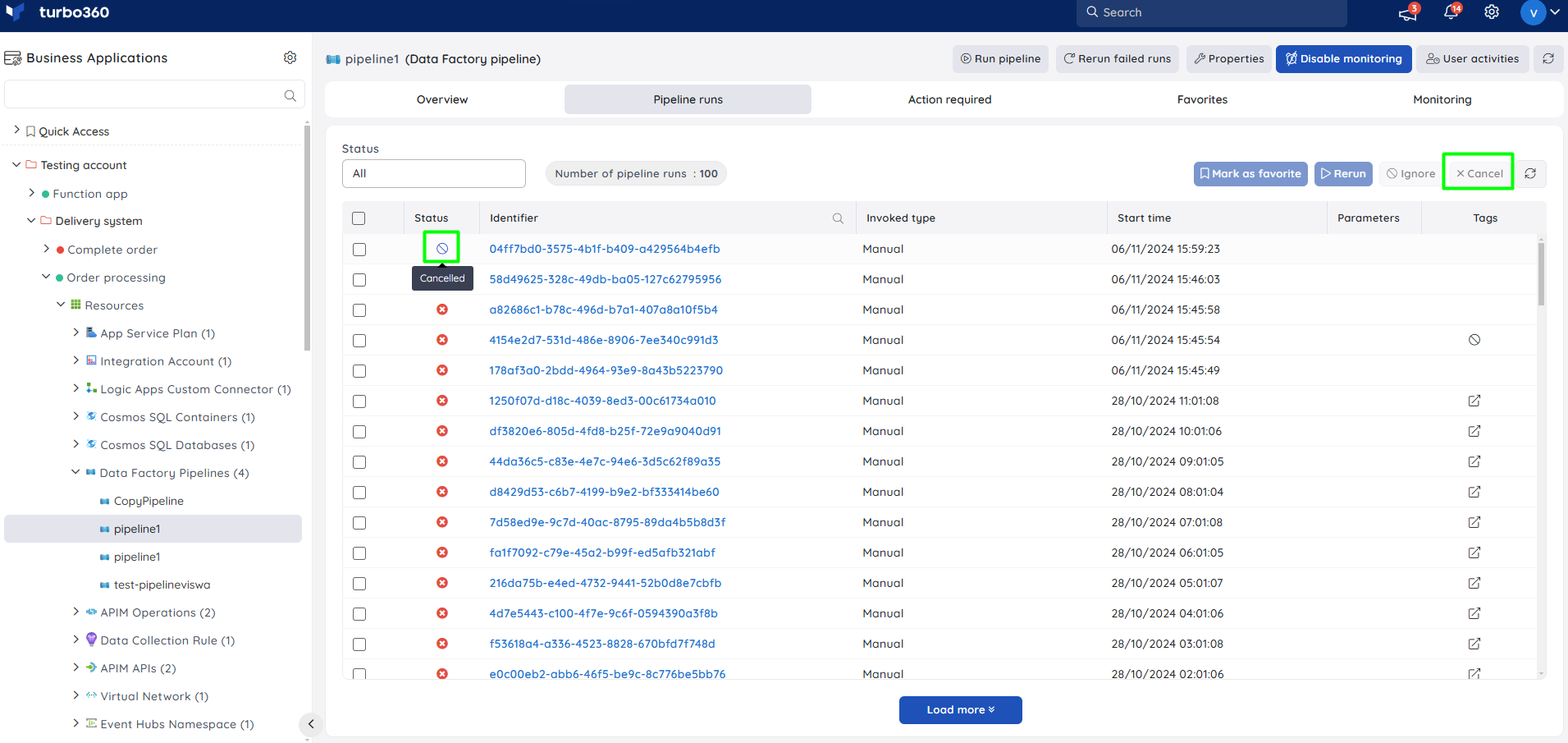
Cancel pipeline run
Users can cancel ongoing pipeline runs by selecting it from the Pipeline Runs tab and clicking the Cancel button.
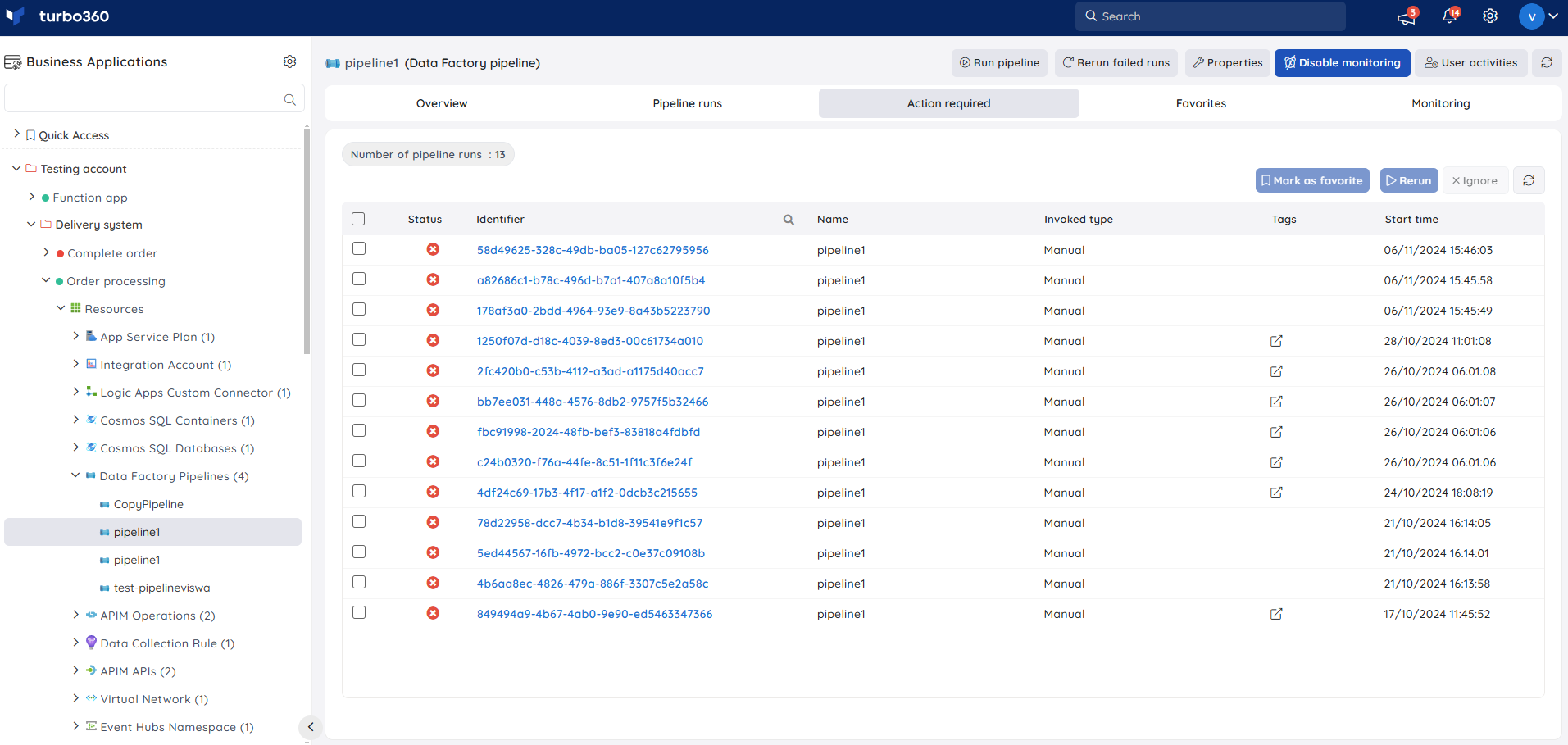
Action Required
Action required helps users to focus on the failed pipeline runs. It provides users the privilege to rerun or ignore the failed activity runs.
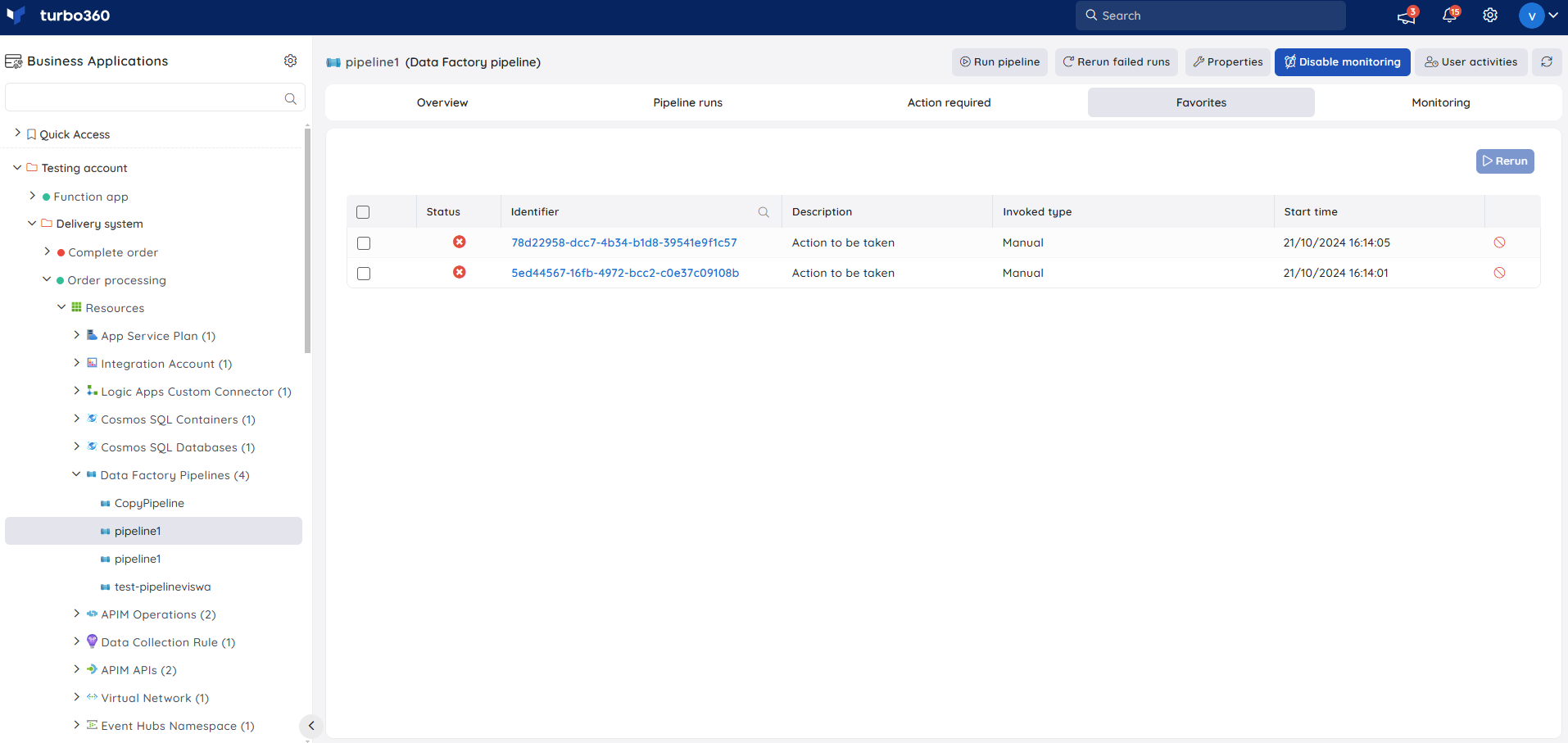
Favorites
Any of the pipeline runs used frequently can be marked as a favorite along with an optional description from both Pipeline runs as well as Action Required tabs.
The favorite runs can be re-run, ignored as well as removed from Favorites.
Integration runtimes
The count of Integration runtime resources connected to the Data Factory pipeline resource will be available in the Essentials card.
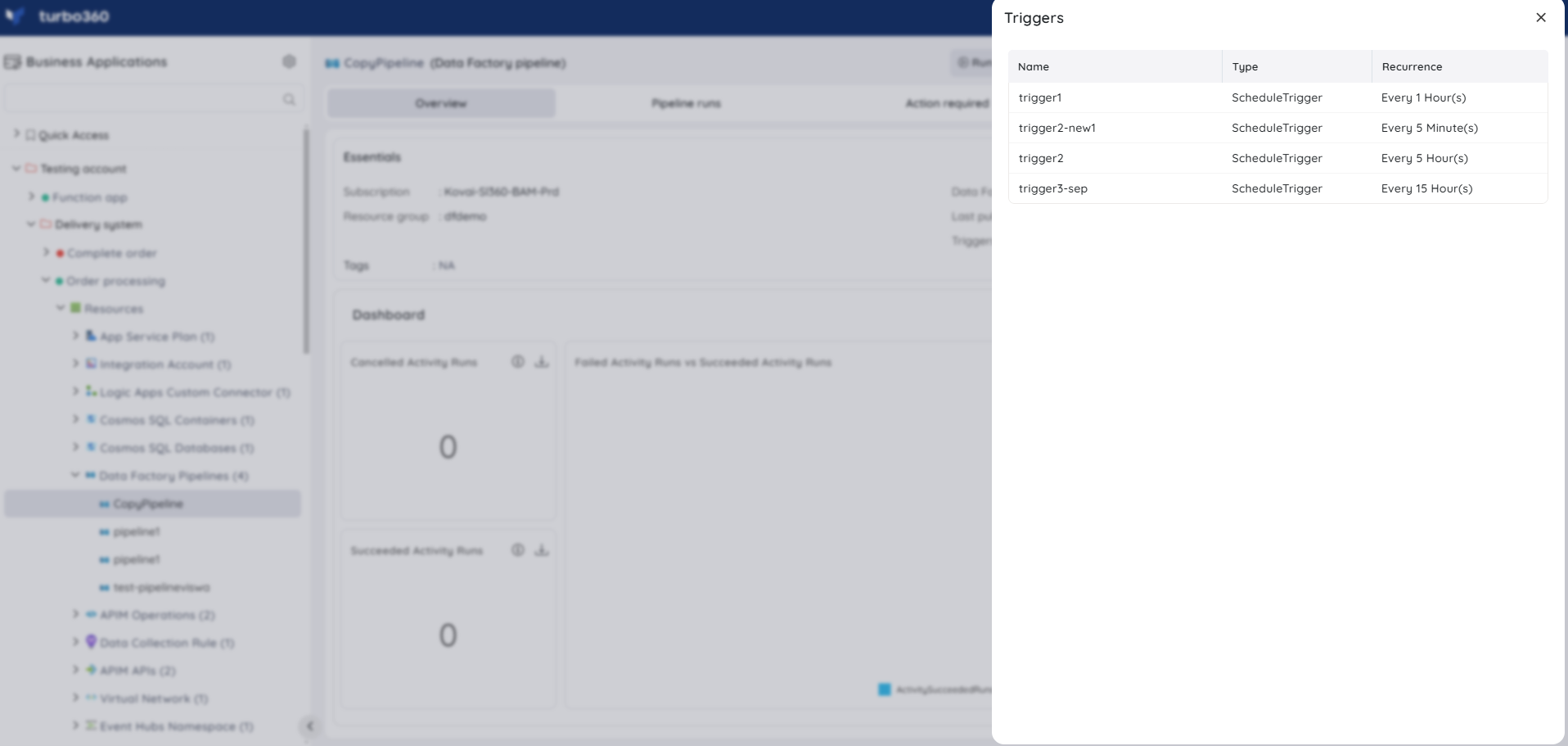
Connected triggers
Users can view the list of triggers associated with a Data Factory pipeline, as well as recurrence data for scheduled triggers from the Essentials card.
Inline task
The Data Factory Pipeline section allows users to quickly re-run failed pipeline runs from the source pipeline that is currently being explored within the specified hours.
The configuration created to run immediately can also be saved for future use in the Automated Tasks section.
Inline task to rerun failed runs
This feature allows users to quickly rerun the pipeline runs that failed within the specified hours (Minimum 1 hour).
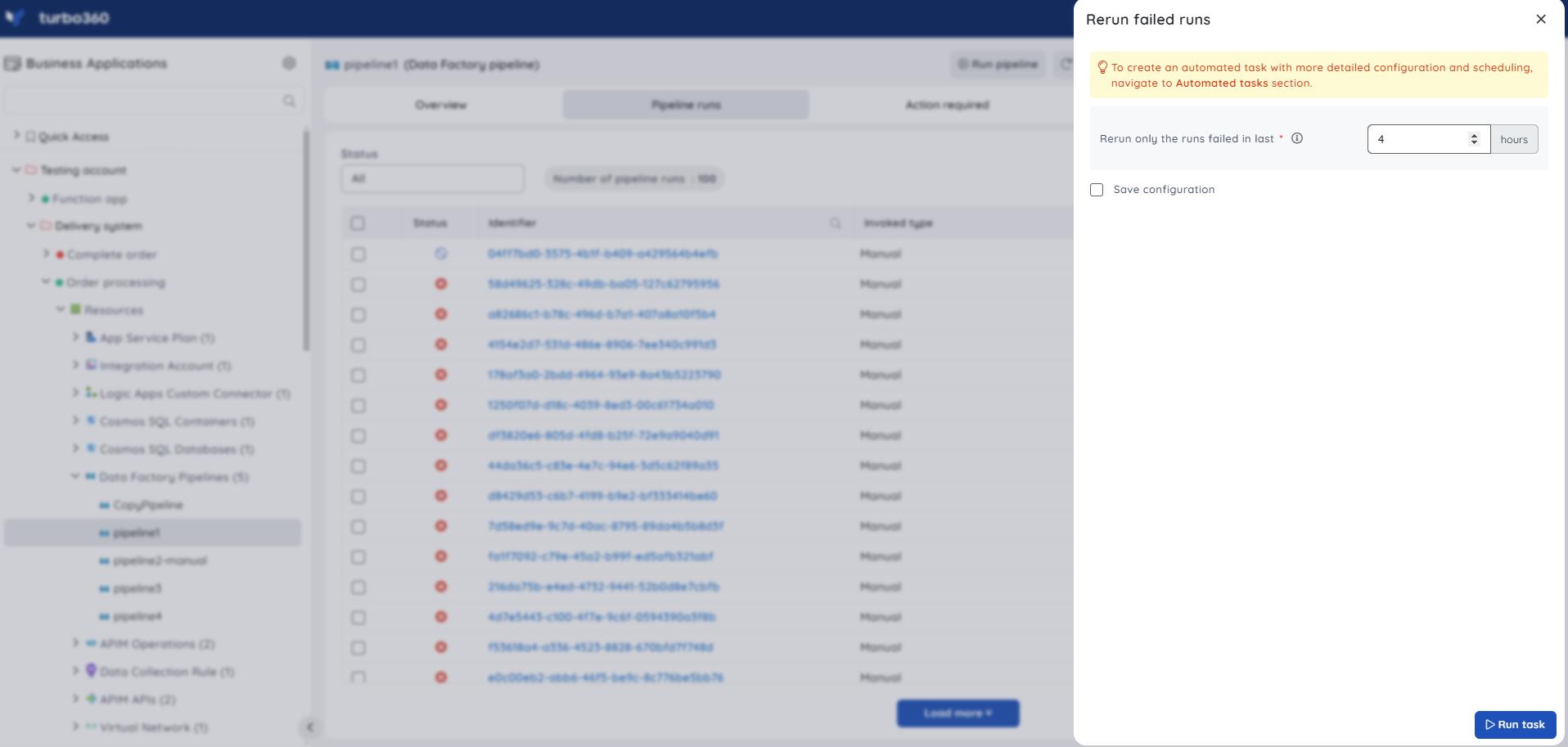
Task status can be viewed by navigating to the Automated Tasks section and switching to the Task history tab.
Users can use this feature to quickly create a task that runs immediately.
Navigate to the Automated Tasks section in Turbo360 to create a task with a more detailed configuration, schedule tasks to run at a specific time, or automate the task to run on the specified hours, days, and more.
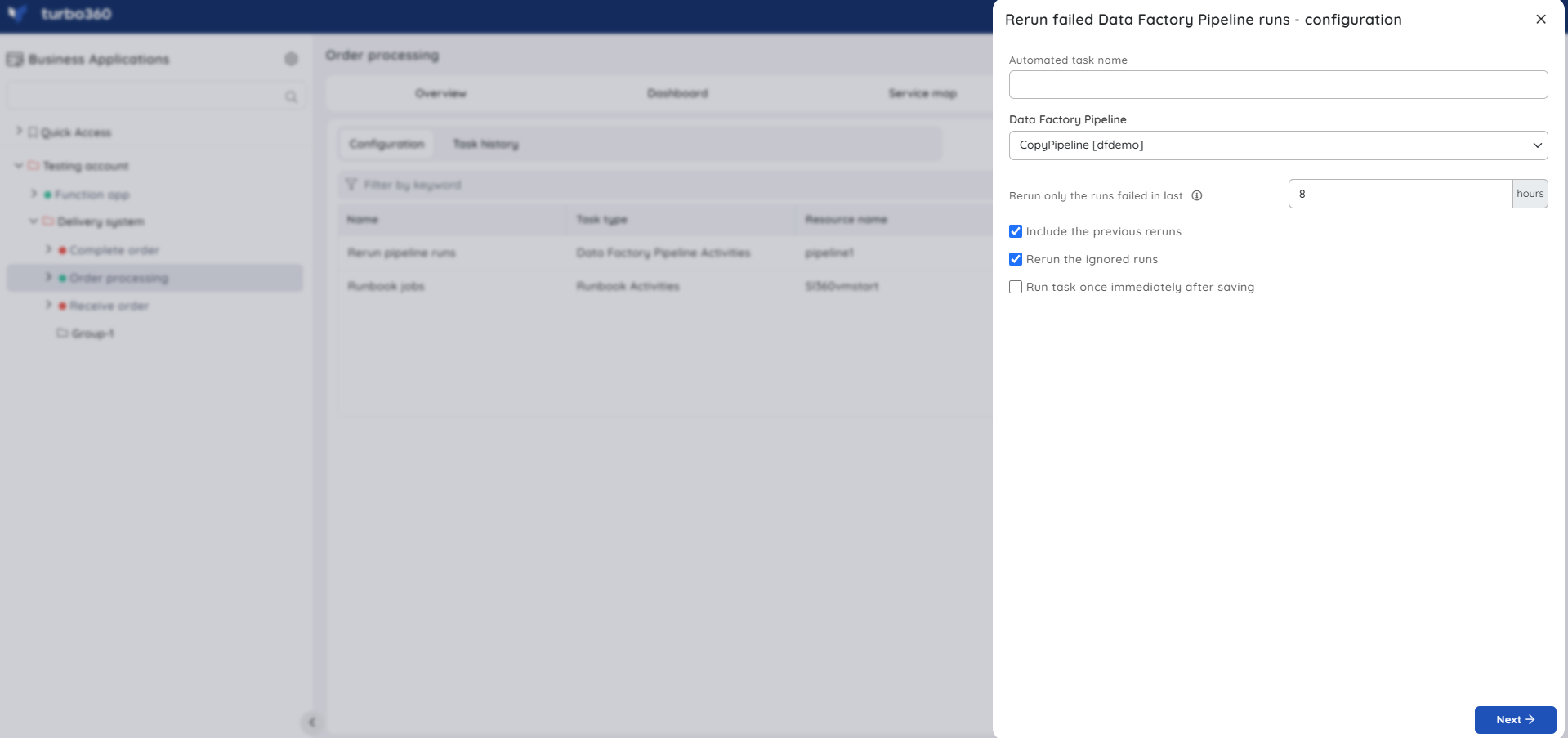
Automated task
The failed pipeline runs can be scheduled to run at a specific time from the Automated Task section with options provided to Include previous reruns and Rerun the ignored runs.
Resource Dashboard
A default resource dashboard is available for Data Factory Pipeline resources in the Overview section, allowing for enhanced data visualization and tracking of real-time data.
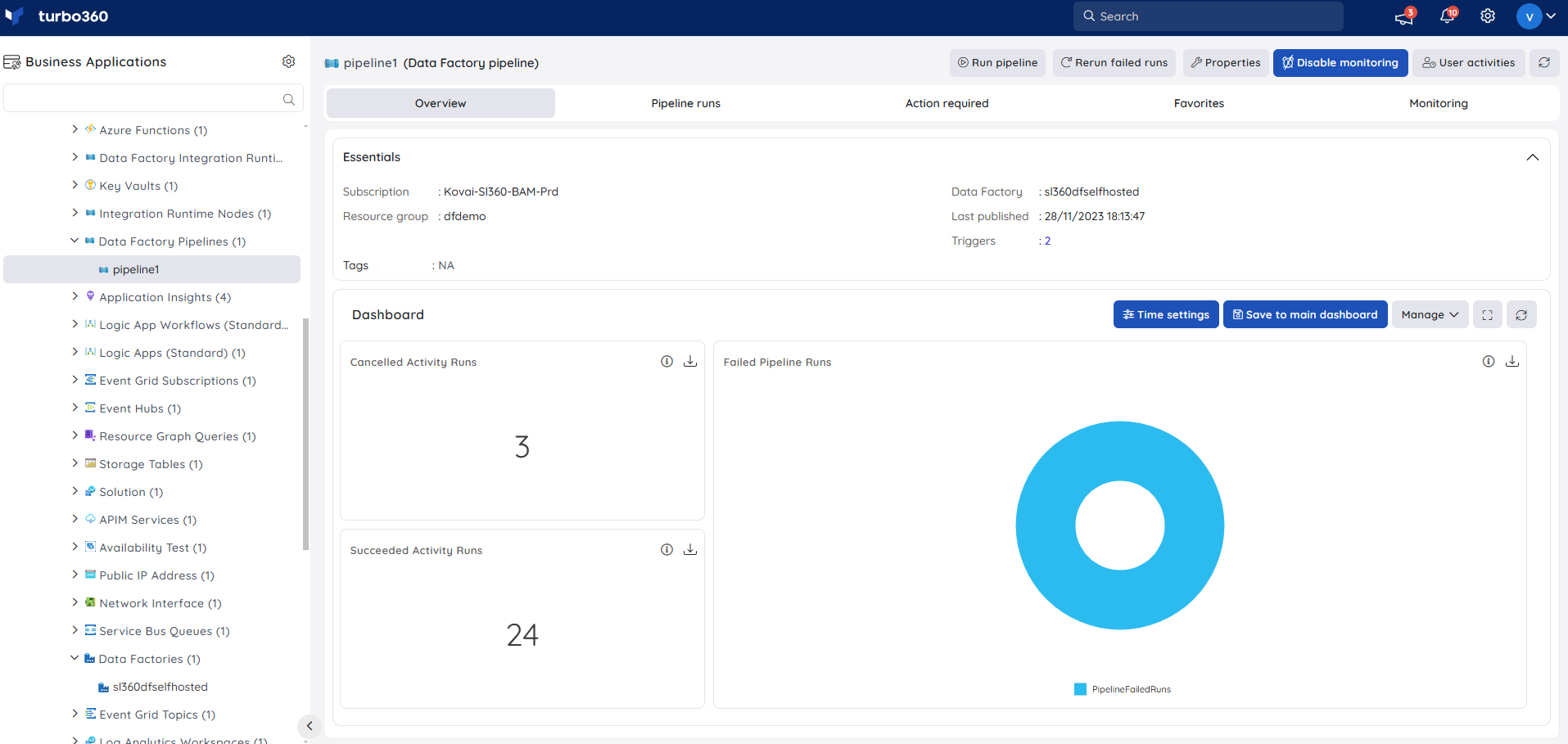
Users are provided with the following pre-defined Dashboard widgets, which can be customized to meet their specific needs.
1. Cancelled Activity Runs
2. Failed Activity Runs vs Succeeded Activity Runs
3. Succeeded Activity Runs
Monitoring
- Navigate to Data Factory Pipeline -> Monitoring to configure the monitoring rules for Data Factory Pipelines.
- Select the necessary monitoring metrics and configure the threshold values.
- Click Save.
The threshold values can also be provided with any metric name, defining the monitoring rule to be violated when the metric value configured at threshold field is met.
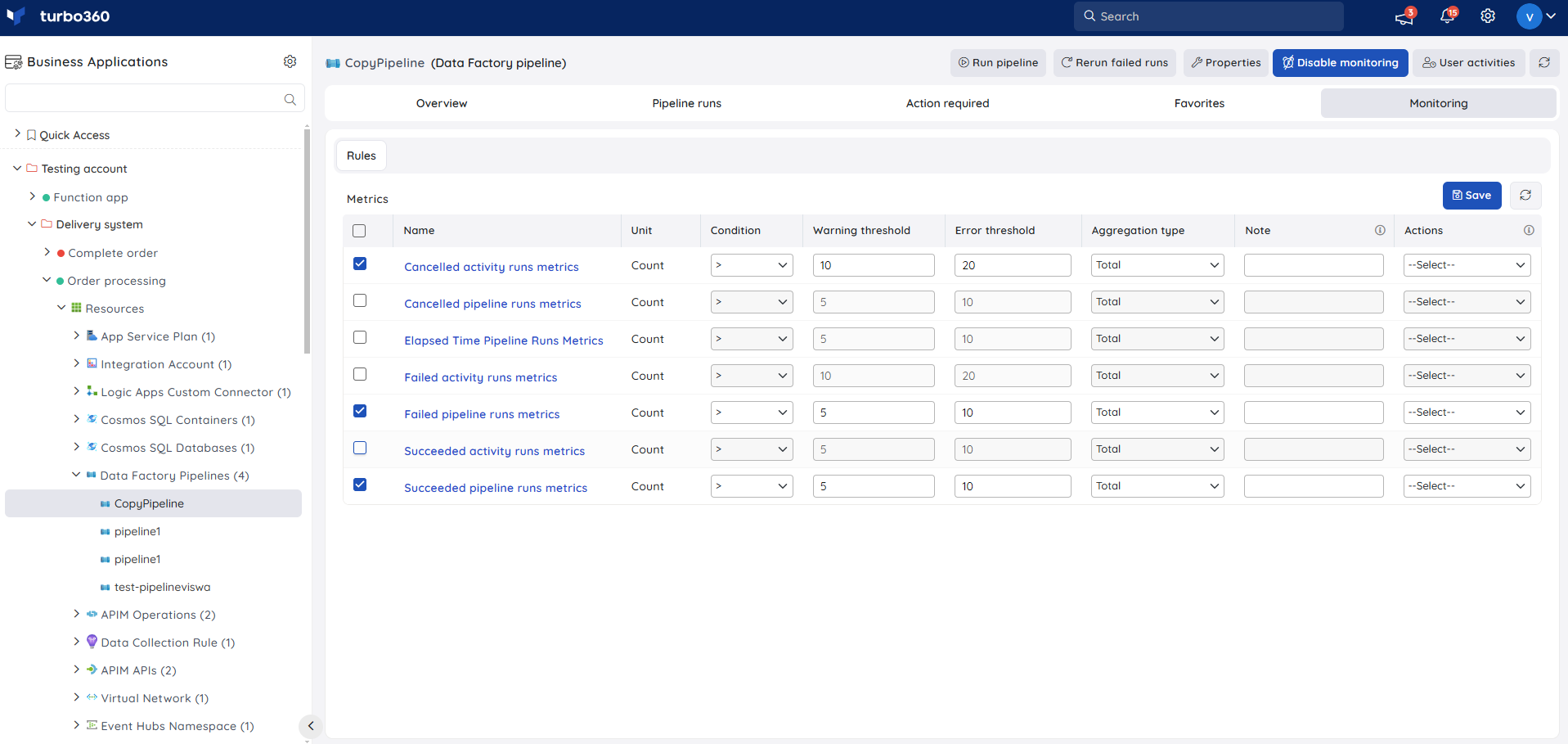
Monitoring rules will be saved for Data Factory Pipeline, and the monitoring state for the metrics will be reflected after every monitoring cycle.
Was this article helpful?